
C++ 20 部分特性尝鲜
前言
2023 年了,C++ 23 都要出了,各大编译器厂家对 C++ 20 的支持终于有点进展了。在 GCC 最近(截止 2023-07-06) 的一次版本更新中,终于添加了对于 std::format 的支持。作为一个坚定的 GCC 追随者,笔者自然是选择 g++ 13.1 作为自己的编译器。(笑)
环境
CPU: 12th Gen Intel(R) Core(TM) i7-12700H
操作系统: Microsoft Windows 版本22H2
(OS内部版本22621.1848)
GCC version 13.1.0 (x86_64-posix-seh-rev1, Built by MinGW-Builds project)
其他的话
笔者希望读者在正式阅读之前,能够记住以下几个要点:
当然,不排除以上是 Codemate 瞎扯的,但是笔者自己的确能很强烈地体会到,C++ 这门语言讲究的就是高效性和包装性。它既要求能拥有和 C 一样的性能,接近底层,也希望能在此基础上提供尽可能多的包装,从而降低方便程序员更好高效的写代码。
简而言之,性能优先,在此基础上提供尽可能多的便利。这大概就是笔者经历了这一年的 coding 后对于 C++ 的理解罢。欢迎各位讨论~
concept&requires
说是话,这可能是我最期待的一个功能了,要想真的想要深入了解,请参考 cpprefence
Background
可能的前置知识: SFINAE
在 concept 出现之前,设想一下,你需要设计一个 sort 函数。一般情况下,你期望用户传入的是一个连续的序列,即数组之类的。很不幸的是,你的用户不一定有这样的觉悟。
1 |
|
对于标准库的 sort 函数,当用户试图传入不支持随机访问的迭代器,就会出现类似下面的报错信息。
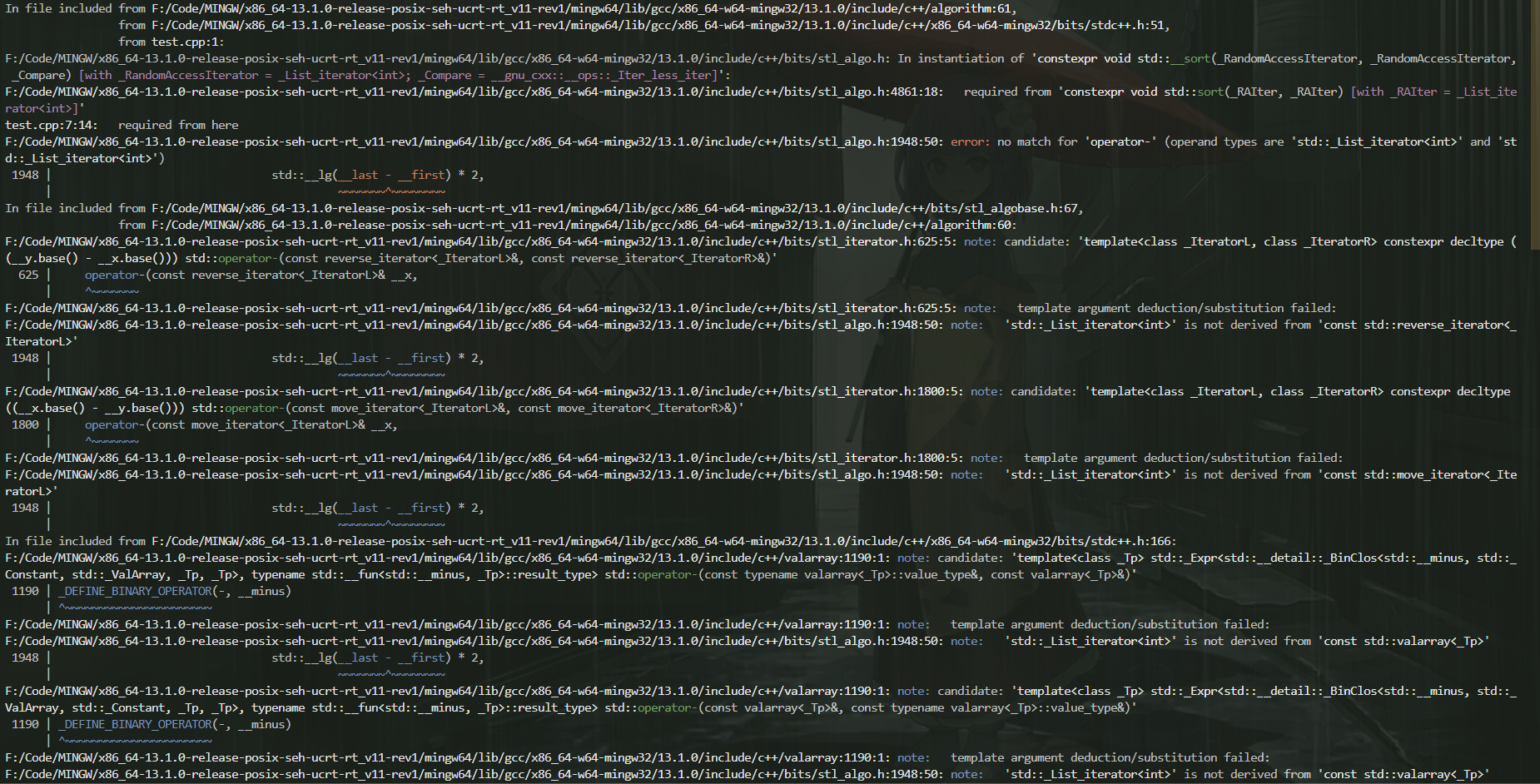
这看起来就令人十分的恼火,太长不看!。而更加令人恼火的是,如果代码补全是 VScode 默认的 C/C++ intellisense ,这破玩意甚至不会提示有错! 原因很简单,因为用户传入的参数匹配上了这个函数模板,而这个模板出错是在编译的时候才发现的,因此你的代码补全机器很多时候不会察觉到这个问题。这时候,聪明的你可能想要对其做出一些针对性的优化。于是,你想到了 SFINAE ,这个 C++ 14 就出现的特性。你把 sort 函数进行了巧妙的包装:
1 |
|
这下好了,对于传入非随机访问迭代器的参数,其在匹配函数的时候就完全匹配不上这个函数模板,因此在编译之前,你的代码补全工具应该就会告诉你: 没有与参数列表匹配的 函数模板 “my_sort” 实例。而编译后的报错信息也会短不少。不仅如此,有了 SFINAE,你可以为其他不满足的类型提供特定的重载。

但是这样的问题也是很明显的。对于每个需要验证传入参数时随机访问迭代器的类,你都要写一个又臭又长的 std::enable_if_t…… 这真的太蠢了!完全不符合代码复用和简洁性!
不仅如此,SFINAE 还存在自己的问题: SFINAE 必须占据函数签名/函数返回值的一部分参数,例如模板参数,函数参数,函数返回值等等。而 SFINAE 占据的参数不能是在函数内部的,本质上还是因为它是在模板进行替换(substitution)操作的时候才检查模板是否可以的。如下是三种常见的 SFINAE 实现方式。
1 | template <class T,std::enable_if_t <std::__is_random_access_iter <T>::value,int *> = nullptr> |
当然,你可以用 void_t 等方式来解决此类问题。但这样的模式还是太麻烦了点,特别是当这个东西耦合入代码,就会使得代码的可读性大大下降,直观性也不足,尽管解决了编译报错信息过长的问题。
最后呢,SFINAE 必须结合模板食用,而很多函数是不能模板化的(例如构造函数等等)。
这时候,concept 和 requires 作为一个替代方案,它出现了。其把函数的约束条件抽象出来,从而极大地增加了代码的可读性直观性,也让重复的工作得以极大的减少。
Definition
concept 最基本的形式如下:
1 | template <...> |
其中,等号右边 concept 是一个可以在编译期就能被估值为 bool 类的一系列函数或表达式,其非常像 constexpr bool 变量。举例:
1 | // 判断是不是原生浮点类型,即是不是 float/double |
而使用一个 concept 有很多种方法。虽然这有点像茴香豆的四种写法,但我觉得还是有必要都了解一下的,当然平时只要会用就行了。
1 | template <class T> |
而 requires ,顾名思义就是 要求 (require) 对于函数模板产生一定的约束(误)。确实是这么一回事,但 requires 不只是这些,其不仅可以后接 constexpr 变量和定义好的 concept (正如前面 lowbit2 函数演示的那样),作为标识符检查值是否为 true,其还可以添加任意的表达式,检验内部表达式是否存在,自身充当一个 constexpr bool 变量。下为伪代码:
1 | requires //含 concept 和 constexpr bool 逻辑表达式,相当于一个完整的语句 |
当然,这么说还是太抽象了点,下面举一些简单的例子:
1 |
|
简而言之,存在两类 requires: 第一种 requires 是 requires 语句, 它检测其后的表达式是否为 constexpr bool true ,如果不满足则直接原地爆炸认为是匹配失败,可以继续尝试匹配其他的模板。第二种 requires 则是 requires 表达式,带有约束列表(以及可能带有参数),其本身会在编译时被替换为 constexpr bool 变量。
什么,你不信? 看看输出的是啥类型。
1 |
|
需要注意的是,concept 不能递归其本身,而 concept 也不能被约束。
1 | template <class T> |
可以看出,concept 和 requires 表达式本质上就是一个 constexpr bool 模板变量,而 requires 语句则是用来辅助 SFINAE 来约束模板类型。在用了 concept 和 requires 之后,代码逻辑变得更加清晰了,SFINAE 不会再和模板逻辑耦合了,再也不用在模板里面放一个又臭又长的 SFINAE 专用参数了(笑)。
Threeway_Comparision
在看这个之前,简单回顾下笔者所认为的 C++ 的核心: 性能优先,包装性其次。OK,那我们来考虑一下以下的情景作为引入:
Intro
现在,假设你实现了一个简单的、支持动态扩容的字符串类,如下所示:
1 | namespace dark { |
作为一个字符串类,除了常见的如 size(),下标访问等接口,自然也是需要支持比较的,而比较的运算符有 >,<,≤,≥,≠,== 这些,于是 string 类型直接的比较就需要重载 6 个函数。当然,字符串比较非常简单,你可以直接调用 strcmp 函数进行比较。看到这里,比较仔细且特别关注性能的读者这里可能已经察觉到了一丝异常,你先别急,后面会分析的。
然而,最麻烦的还不是这个。作为字符串类型,自然要为原生的字符数组类型 char 提供支持,具体体现在可以由原生的 char 数组构造 string,且 string 必须支持和 char 进行比较等操作。然而,重载 string 和 char 的比较有两种情况,string (比较运算符) char ,以及 char (比较运算符) string 。在 C++ 中,你必须为这两种情况都分别提供特殊的重载,否则,string 和 char 在比较的时候,char 可能会调用隐式构造函数,转化为 string 类型,而这多了一层不必要的开销!
这样的话,不出意外,你需要写 6 3 个比较函数。这也太重复了吧! 事实上,对于任意两个字符串的比较,其总是可以归结为两个 const char 进行比较,因此我们可以借助 strcmp 函数来实现,代码类似如下:
1 | bool Compare_Less(const char *x,const char *y) { |
事实上,这背后还有不少的小麻烦。当你将两个字符串绑在一起,作为一个 pair 的时候,你的比较函数的重载将会非常麻烦。如果按照传统的写法,那可能是这样。
1 | using pair = std::pair <std::string,std::string>; |
此类写法有一个巨大的问题,那就是前两次比较其实可以一次完成: 如果某个比较操作可以直接明确地返回两个数的相对大小关系,并且开销和一次比较差不多,那么我们用这个比较的结果就可以直接代替前两次比较,将开销较大的两次 string 类转化为一次 string 类比较加上开销较小的若干次 int 值比较,如下所示:
1 | using pair = std::pair <char *,char *>; |
当然,这种写法对于数据的要求略高,不是所有类型都像 string 那样,有一个统一的比较函数接口。
究其根本,其实是语言上缺少一种一个通用的接口,可以直接返回两个类的明确的相对大小 (即一次性不花费额外开销,得到究竟是小于,还是等于,还是大于的大小关系) 。小插曲,DarkSharpness 在写 map 的时候就意识到了这个问题,只可惜大部分的 map 要求的是 < 重载。为此,Dark 在后续 B+ 树作业中就要求传入的类自带 Compare 函数,可以返回确定的大小关系,当然这么写很不自然也很丑陋……
总之,过去的 C++ 比较存在如下问题: 需要重载很多的运算符,且不存在统一的可以一次比较出两个数相对大小的方法。
Solution
在 C++ 20 里面,终于推出了宇宙飞船三路比较运算符,作为比较相对大小的统一接口吗,可以说是一个最为优雅的解决方案。
当然,标准库在此基础上还加强了这一比较运算符。其返回的不是 int 参数,而是返回特殊的比较类别: std::strong_ordering / std::weak_ordering / std::partial_ordering ,对应的是强序关系,弱序关系 和 偏序关系。
强序关系表示任何两个该类的对象都可以比较得出相对大小,且等价(equivalent)的两个对象完全相等(equal),即这两个对象的值是不可辨别的。整数类型便是典型的强序关系。
弱序关系表示任何两个该类的对象都可以比较得出相对大小,但等价的两个对象不一定是不可辨认的。例如,将整数按照二进制位中 1 的个数排序,其满足的就是弱序关系。
偏序关系表示两个该类的对象不一定可以比较得出相对大小。例如浮点类型,因为 NaN(not a number) 不能和其他任何东西比较。
需要注意的是,等价(equivalent)和相等(equal)往往会被混淆,这可能是因为各位平时都习惯了强序结构……偶尔看看英文还是有好处的,有助于区分某些概念(好吧当年学英语的时候,这两个词也搞了 Dark 一段时间)。
在使用三目运算符的时候,可以简单的将三目运算符的返回结果和 0 进行比较。如果 < 0 ,那就是小于关系。如果 = 0 ,那就是等价(或相等)关系。否则,就是大于关系。其用法类似 strcmp 函数,这里就不多阐释了。代码如下:
1 | struct custom { |
Bonus
如果只有三目运算符,并不能称得上什么大革新,只能说为了性能做出的一个统一接口罢了。C++ 20 在三目运算符的基础上,还推出了自动生成运算符的方法。
是的,只要类里面实现了三目运算符,C++ 就会自动为我们生成包括 >,<,≤,≥ 这四个常见的 operator 。同时,C++ 也提供了默认的三目运算符的方法,其讲按照变量定义的顺序,数组的下标从小到大,逐一去比较两个类的成员,类似字典序。
1 | struct conless { |
需要注意的是,当你使用 default 三目运算符的时候,最好将返回参数设置为 auto ,编译器会自动地决定其返回类型。返回类型当然取得是比较类型中最弱的那个,比如上面例子中 conless 类中,最弱的是 double 数组的 double 变量,是 std::partial_ordering ,因此 auto 推导的类型就是 std::partial_ordering 。特别地,如果存在一个成员类型,其是不可比较的,那么 default 生成的该函数返回类型是 void,因此编译器不会自动生成其他的几个比较函数。
讲到这里,细心的你肯定已经发现了: 为什么不会帮我们自动生成 == 和 ≠ ? 这背后其实隐藏着一个性能问题:
在你比较两个 std::string 类型变量是否相等的时候,思考一下你会怎么做? 你会先比较长度! 是的。你不会统一的按照字典序的方法去比较,你当然会先比较长度,如果长度不同那么其显然不会相等。这是一个非常显著的优化。
因此为了性能,C++ 不会让默认的三目运算符生成 == 和 ≠ ,即使你依然可以通过 (x <=> y) < 0 来判断两个变量是否相等。当然,为了便利性,C++ 也提供了 == 的默认生成方式来生成默认的 == 和 ≠ 运算符。
Implement
不得不说 gcc 对于三目运算符的实现还是非常有意思的。首先,要使用三目运算符,需要一个 <compare > 头文件,这个头文件里面有关于 std::strong_ordering 等序结构类的定义。
通过查看头文件,我们不难发现,其实所谓的大于小于等于的关系,都是用一个 char 变量来表示,其值可以是 -1 (less) 或 0 (equal/equivalent) 或 1 (greater) 或 2 (unordered)。
不过问题出现了: 你要支持序结构和整数 0 之间比较的操作,例如 (x <=> y) == 0 。但是,如果为序结构提供一个转化为整数的接口,或者为整数提供一个转化为序结构的接口,都会带来各种不安全。那么,如何不依赖编译器,只借用库文件就能实现一个好的序比较呢? 这里就用到了一个 C 语言的 trick:
字面量 0 , 其在语言中可以被隐式的转换为空指针类型,类似于 nullptr 。事实上,这一设计存在某些问题,经常被人诟病,这也是为什么我们有了 nullptr。但是,在这里,比较的实现用到了这个 trick。标准库实现了一个虚空代理类 __unspec ,其没有任何成员,唯一的构造函数是传入自己的指针:
1 | struct __unspec { |
而众所周知,0 可以隐式的转换为空指针类型……因此,事实上,你在比较的不是 0 , 而是一个 __unspec 对象,通过这个对象和序对象的比较,我们间接的得到了内部的大小关系信息。
当然,你可能觉得这样太过奇怪。没有关系,标准库也提供了其他的接口来提取出大小关系,如下:
1 | auto cmp = 1 <=> 2; |
format
感谢 g++ 13.1 提供的对于 format 的支持,终于可以用了!
Past
在过去,标准的输入输出一般有两种途径,一种是 C 语言风格的 scanf/printf ,另一种是 C++ 风格的 std::cin 和 std::cout 。前者可以根据格式串输入输出,后者则是通过类的重载进行输入输出。
但是,两者都存在一定的问题。相信大家在作为初学者的时候,肯定有遇到 scanf/printf 格式串写错,参数写错等一系列的问题吧。比如:
1 | long long x; |
这样的错误并不会有任何报错,甚至可能不会在运行时有任何的异常出现,直到遇到一些极端情况,出现莫名其妙的错误……
此类错误 debug 起来并不是非常容易,特别是当程序非常庞大的时候,由于编译器没有报错信息,定位到输入输出出错需要相当长的时间。
然后是 std::cin 和 std::cout 。尽管其做到了 typesafe,但其性能问题被诟病已久,即使在关闭了流同步以后,表现依然不是非常好。
然后是可读性,很难理解为了给输出表达式加括号,你需要在两边单独输出两个字符……
1 | std::string str = "Hello World!" |
因此,长久以来,C++ 社区就存在呼声,要有 scanf/printf, std::cin/std::cout 之外的标准 inout 手段,不仅要高效,而且要 typesafe。
事实上,对于 OIer,他们中的很大一部分,甚至都手写了快速读写函数,而不屑用标准库的输入输出,这就已经足以说明一部分问题了。
fmtlib
fmtlib,一个现代的第三方 C++ 库,其提供了格式化输出字符串更加高效的写法。由于其完美兼顾了 typesafe 和高效的两方面特点,其也因此被部分的并入了 C++ 20 的标准库中。
由于功能过于繁多,这里挑取其部分特点进行介绍。
Basic-Usage
首先,我们来讲讲他怎么用吧。非常简单,他和 printf 非常像,要提供一个格式串和参数列表。但是格式串,其远简单于 printf , 其没有必要加上 %d %f 之类的参数 ,只需要用 {} 即可。输出的则是 std::string,又有点像是 sprintf。如下:
1 | // str = "1 2" |
特别地,当你要输出一个字符 { 或 } 的时候,只要重复一遍即可,如下:
1 | // str = "{1 2}" |
当然,其功能不止如此。如果你想要进一步的操纵输出的变量,你可以在 {} 内部添加新的参数。形如: {index : rule} 。第一个 index 表示输出的变量所在的下标。当默认括弧内无参数的时候,其输出顺序就是从左往右。当括弧内存在 index 参数的时候,所有括弧必须都有 index 参数,且输出顺序按照 index 顺序。当只有 index,冒号可写可不写。特别地,这玩意甚至支持复用! 如下:
1 | // str = "1919810" |
而冒号后面的内容,则是具体格式串的要求。如下:
整数:
| 格式 | 含义 |
|---|---|
| d | 十进制整数 |
| x | 小写十六进制整数 |
| o | 八进制整数 |
| b | 二进制整数 |
1 | std::cout << std::format("{0:d} {0:x} {0:X} {0:o} {0:b}\n", 114514); |
浮点数:
| 格式 | 含义 |
|---|---|
| f | 固定点表示法 |
| e | 小写科学计数法 |
| E | 大写科学计数法 |
| g | 选择最简表示法(f/e) |
| G | 选择最简表示法(f/E) |
1 | std::cout << std::format("{0:f} {0:e} {0:E} {0:g} {0:G}\n", 1919.810); |
字符串:
s 表示字符串……
1 | std::cout << std::format("{:s} {:s}\n",std::string("yyu"),"yyu"); |
其他输出设置:
| 格式 | 含义 |
|---|---|
| < | 左对齐 |
| > | 右对齐 |
| ^ | 居中对齐 |
| 数字 | 指定输出宽度 |
| 字符 | 指定填充字符(用来填充到指定宽度) |
| .数字 | 设置输出精度/最大字符串长度 |
| + | 正数输出 + 号 |
1 | std::cout << std::format("{0:_^10s}\n{0:_<10s}\n{0:_>10s}\n","yyu"); |
除了 format,标准库还提供了 format_to 函数,其可以把格式化的结果输出到一个 char 数组当中。其功能类似 sprintf,但是性能更优,且支持自定义解析,而且类型安全。
Compile-Time-Parse
format 库最大的特点是它支持的是编译期解析,也就是其解析格式串的过程是 0 运行时开销的!
这是因为其传入的参数必须是 constexpr 的,或者说 consteval 的字符串,即必须在编译期间确定值的字符串。因此,其可以借助 constexpr 函数以及模板,
由于 Dark 实在是太菜懒了,所以具体的实现咕咕了。感兴趣的可以去看看 std::basic_format_string 这个类 qwq。
当然,你可能会想: 我们如何为自定义的类型使用自己的 format 格式呢? 这就需要用到自定义的 formatter 类。
由于时间问题,这里留给读者自行研究 qwq。
const
这部分是关于 constexpr,consteval 和 constinit 的。由于 DarkSharpness 太咕咕了,于是这部分就没了。v 我 50现在就写
后记
想看啥直接发评论区,有啥讲的不好的欢迎来喷 Dark 教授,真的都可以说的,Dark 教授非常欢迎您指出错误 Orz!
当前计划列表: std::span , consteval/constinit ……
参考资料: C++20 STL Cookbook 2023 , cppreference
 Wechat
Wechat






