
一些关于常数的玄学优化
2023-02-03 更新了STL容器基础优化一点点内容
注意,本文提到的优化大多是在基于程序复杂度正确的情况下对于一些常数的优化,本质是只是一种奇淫技巧,请勿滥用。所有测试数据全都是基于笔者的破电脑,且受随机因素影响,仅供参考。
前言
时间复杂度 = Everything?
一个程序的快慢取决于什么?你可能会说是时间复杂度。的确如此,在大的数据量的情况下,渐进复杂度更优的算法肯定会跑的比更劣的快。(注: 在本文中的复杂度默认是 大O 时间复杂度,用数学语言表述即假设一个程序的实际运行为$T(n)$,$\exists N,c\in \mathbb{R}, \forall n \in \mathbb{N},n \geq N ,s.t. \ T(n) \leq c * O(n) $ )。我们常常会忽略其中的常数 $ c $ ,这在渐进意义下是没太大的影响的。但是,在应用场景下,往往输入的数据规模并不会太大,在这样的情况下,算法的常数便会变得不可忽略。
举个不太恰当的例子,我们假设有一个很快的处理算法,其执行时间是 $T_1(n) = 1000 nlog_2n $ ,也有一个朴素的暴力做法,其执行时间是 $ T_2 = 0.5 n ^ 2$。此时,当 $ n \gt 29718 $ 的时候,第一个方法才会优于 第二个方法。单从时间复杂度上来看,第一个操作是 $ O(nlogn) $ 的,理应优于第二个 $O(n^2)$的操作。但是,受制于常数过大,只有当数据量足够大的时候,其才显得更加高效。而现实中,需求的数据量可能并不会达到这么大,这也会使得第一个算法变得无用。
一言以蔽之,就是算法本身的时间复杂度固然重要,但其常数也不可忽略,而具体如何取舍取决于数据量的大小。
常数优化的意义
常数优化在OI中意义并不大,在大多情况下OI追求的是算法的正确性,而不会刻意去卡常数。但在实际运用中,一些细节处的常数可能会导致巨大的时间差异。例如作业ICPC管理系统中,若不进行适当优化,则很容易使得程序运行常数增加 $m$ (最大为26,故可视作常数) 倍,这会使得 AC->TLE
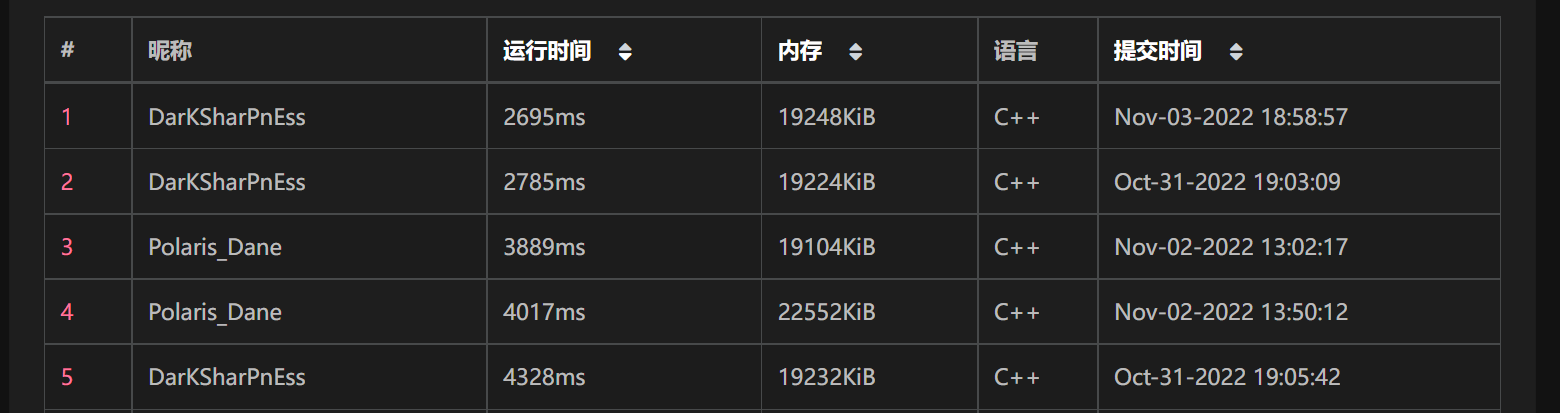
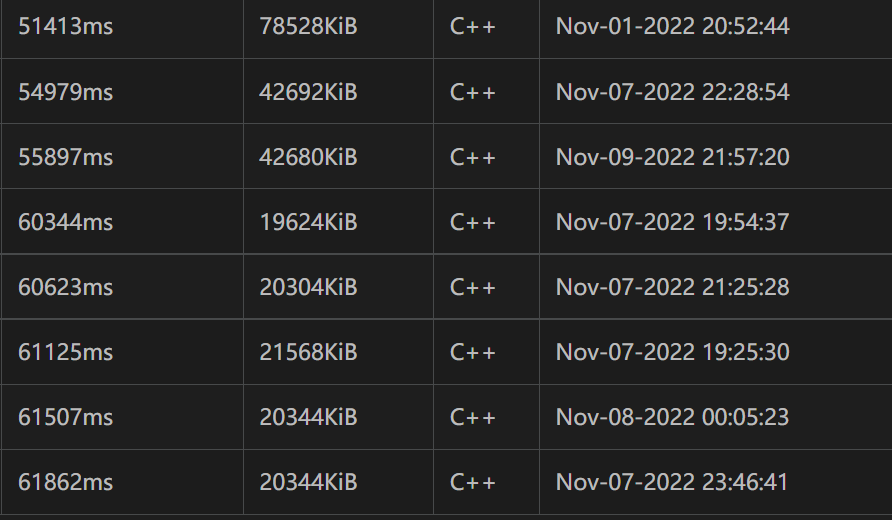
如果是真实的项目(例如手机APP),20倍的常数差异可能就意味着客户等 0.1s(几乎无卡顿)和等 2s (是个人都能看出的卡顿)的区别,为了您的客户、钱包还有打榜的快感 ,常数优化显得十分有必要。
认识常数优化
笔者是菜狗,不会汇编,对更深层的优化不太了解,所以只能分享以下一些简单的入门级优化。
再次声明,本文内容不保证100%正确性,只是笔者一家之言,具体表现还会受到随机波动以及测评环境不同带来的影响。
测评环境
CPU: 12th Gen Intel(R) Core(TM) i7-12700H
基准速度: 2.30 GHz
插槽: 1
内核: 14
逻辑处理器: 20
虚拟化: 已启用
L1 缓存: 1.2 MB
L2 缓存: 11.5 MB
L3 缓存: 24.0 MB
操作系统: Microsoft Windows 版本22H2
(OS内部版本22621.819)
GCC version 12.2.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project)
认识常数
常数的确是一个非常玄学的东西,在正常的算法书上一般不会去分析,它也很难量化到具体的数值,因为影响它的因素确实太多了。在这里,我们定义常数 $ c = \frac{T(n)}{O(n)} $,其中 $O(n)$ 无常数的多项式,默认 对数以2为底数 (下将简记为$ logn $)。
笔者参考了一下2009国家集训队论文中骆可强所著的《论程序底层优化的一些方法与技巧》,认为常数大致与以下几个方面有关:
- 机器本身程序语句在底层运行的消耗
- 算法本身设计的消耗(即含有多少次加减乘除之类)
- 问题的数据规模(即前文的 $n$ )
值得注意的是,由于笔者对于常数的独特定义,其可能会与数据规模 $n$ 有关,但是其仍然需要满足 $\lim_{n \to \infty}c = constant $ 这一基本性质。
如何减少常数(基本运算篇)
重要的事情说在前面:
重要的事情说在前面:
重要的事情说在前面:
以下测试均基于C++ rand() 产生的随机数,所有操作若未特定说明默认为int类型。(如果是更长的类型long long且在64位操作系统上运作,则大致可认为效率与int相当,实测差距几乎不会超过1.5倍。)
由于机器本身程序语句在底层运行的消耗是不太可控,我们将主要从算法本身设计的消耗进行分析。像加减乘除位运算以及赋值等基础操作,你显然无法进行直接优化,但你可以通过了解一些基本的原理来减少程序主体的常数。
整数的位运算和逻辑判断
计算机底层是通过位运算和赋值来进行操作的,因此最快的操作是位运算和赋值语句以及逻辑判断。位运算包含了: 异或 ^ , 或 | , 与 & ,取补 ~ ,左移 << ,右移 >> 。 逻辑判断则是一切含 == < > ! 的判断语句。
以上具体可以体现在当你要快速求出2的n次幂的时候可以简单的使用 1 << n,而不是用快速幂或者库里面的pow函数。同时,对于取出特定的二进制的值,特别是在一些涉及状态压缩 dp (即把状态用二进制数来存储表示)的题目里面,需要频繁用到位运算。(事实上,这应该是一些基础知识,而不是玄学)。当然对于对2的取模或者除法也因此可以优化。
以下列举了一些作者 OI 里常用到的位运算
1 | int i,n; |
附:若要更深入了解运用位运算,读者可自行查询 STL bitset 相关内容 ,这玩意可是卡常利器。
整数的加减乘除模
整数的加减乘除模是除了位运算和逻辑判断之外的计算机的基础操作,其效率并比不过单纯的位运算,但也没有想象中那么拉跨。
在加减乘除模这五个最基础的操作中,加法和减法的时间开销几乎相差无几,可以认为相同。而乘法作为现代CPU的基本运算操作之一,其速度也较快,可以认为和加减法相差无几。笔者实测波动较大,估计时间消耗为加减法的1.0 ~ 1.3倍(仅供参考,实际中甚至出现过随机数乘法快于加法的逆天情况),这也告诉了我们,我们完全没有必要刻意的优化一个乘法过程。而相比之下,除法和取模就是相对较慢的过程,笔者实测两者效率大致相同,平均比加法要慢上个 2 ~ 4 倍,并没有网上传言的 10 多倍那么恐怖(当然,这可能因机器而异)。
针对除法取模慢的特性,我们可以通过减少其操作次数来极大地减小常数。除了之前讲到的位运算等操作,产检的做法还有推迟取模。例如一个程序过程中如果要对一个数取模,在保证不会爆存储类型(int或long long)的范围的情况下,可以在运算过程中尽可能减少取模次数,而在最后对答案统一取模来减小常数。事实上,这一操作是值得的,你甚至可以为此把int换long long来防止爆范围来换取更少的取模次数。
消除逻辑分支
在现代计算机中,逻辑分支其实是个比较慢的过程,其包括if/else if/else的分支,for/while的分支,以及三目运算符 ? : 的分支(注:其不是逻辑判断,逻辑判断是一个很快的过程;goto本文不涉及)。其背后是因为CPU是像流水线一样的在工作,一条指令还没结束的时候,后面的许多指令也以及开始执行。但当CPU遇到分支的时候,它无法知道后面会要执行哪个分支的语句,因而会暂停流水线,直到分支走向确定。尽管现代CPU早已拥有了强大的分支预测的的操作,对于有规律的分支会进行较为准确的预测,但在完全随机下其还是一个相对缓慢的一个过程。但是,我们完全没有必要为了逻辑分支而用加法替代,现在逻辑分支依旧是一个非常高效的过程。
以下给出一些笔者常用的方法。
- 短数据打表
1 | //返回类型为std::string的函数 |
值得一提的是,这个优化在strMap用char *来存的时候如果开O2会失效,因为-O2优化会省去if过程中的std::string构造函数的过程,但对于数组中的元素初始化str,其构造函数无法略去。这也启发我们: 在优化时开的数组要用和赋值时一样的类型,以尽可能避免类型转换带来的开销。
同 时,这个优化在开-O2的情况下对短数据类型例如int和long long是负优化,但在非-O2的情况下却是正向优化,笔者暂时还未分析出原因(怀疑和数据8-byte对齐相关),如果您知道为什么,欢迎来告诉本蒟蒻orz,不胜感激。
总结: 若无任何优化可以大胆使用该优化,在-O2的条件下可以适当的对非基本数据类型,例如std::string等通过打表了消除分支。在有效优化的情况下效率大约能达到两倍
- 在程序主题逻辑实现上减少预测分支数量
假如有一个if和for循环嵌套,如果if的判断独立于for循环,请把if判断提前,for循环写在if之中,这样可以减少循环次数 - 1次的判断。
同时,对于大量情况的 if/else if/else 语句,如果有可能请换为 switch/case 操作,switch/case 本质是跳转表,相比多个 else if 更为高效。笔者一般对于超过4个情况的 if 语句就会转化为 switch/case ,这么写不仅会更高效而且直观性也会更好。需要注意的是case:后会进行到底,若要用于替代 if 语句请记得break;
若还想追求极致的效率,可以自行搜索__builtin_expect 函数、[[likely]]和[[unlikely]](C++20),这里先不展开了。
如何减少常数(C++特性篇)
除了程序底层运算层面的优化,了解C++语言,我们也能极大的减小程序的常数,这包括了C++内置的一些函数以及语言自带的一些features,也涉及编译器的一些底层原理。
输入与输出优化
这个是为较多人所知的一点,即C++最常见输入和输出工具 std::cin 和 std::cout 其实非常缓慢。这是因为 cin cout 在标准库中要求与 C 的输入输出工具 printf,scanf等同步,而这会带来一些额外的开销。最简单的办法就是关闭流同步,只需要 std::ios::sync_with_stdio(false);一句即可,可以让cin cout快2 ~ 3倍(纯经验,仅供参考!)。这样的副作用是不能cin/cout和scanf/printf/getchar/putchar/puts混用,要么用C++的输入输出,要么用C的。
以上优化可以把cin/cout提升到远超过scanf/printf的效率了,而且在本地测试的时候,实际上已经比普通的快速读入(手写read())要快了不少了(大约1.2倍)。然而,在各大测评机中,貌似还是手写的快读来的快。这里提供个作者写的板子。
1 |
|
常量修饰(const 和 constexpr(C++14))
C++的const和constexpr是一个非常有趣的东西,被const和constexpr的值是不可修改的,因此编译器会对其进行较大的优化。这是因为对于固定整数的运算可以简化为更基础的运算,这点在取模和除法上有极好的体现。
具体来说,经过编译器优化(即使没开-O2),对固定constexpr/const常数的取模和除法会被优化为一系列位运算,加减和乘法操作,这样可以使得取模和除法的时间大大减小。
1 | const int mod = 1000; // 常数请务必加上const |
更加深入的,如果你要对几个常数取模或除法,请不要将其用数组存,并且函数中用参数决定是对哪个常数操作,因为这样的话编译时无法确定需要进行哪个操作,这样无法进行常量展开优化。以如下快速幂为例。
1 | constexpr int mod[2] = {114514,1919810}; |
笔者给出的解决方案有两种:
- 使用模板展开(即
template <int type>) - 手动展开函数(即写多个版本)
这样操作以后在非-O2环境下优化不明显,但是一旦开了-O2优化,效率能达到未展开时候的2倍。
1 | constexpr int mod[2] = {114514,1919810}; |
STL容器基础优化
很多人都觉得STL容器很慢,但这是他们的错觉。在开了-O2的情况下,正确使用STL容器是可以跑的很快的,你甚至可以骗到很多的分。(如果你还不会STL,可以看看这篇浅谈STL)
首先,容器是用于存储、维护数据的结构,其内部往往含有很多元素。如果我们像基础的数据类型那样随便开变量赋值,那么运行时开销将会巨大,这是因为容器赋值的过程中需要将元素全都赋值一遍,这个过程时间复杂度正比于容器内元素个数,很容易使得常数翻很多倍,应当避免。正确的做法是在能够引用传递参数的地方都应该使用引用传参。
1 | vector <string> vec; |
同时,若明确的知道一个容器内的元素无用了,我们在赋值时应该使用std::move把这个元素变为右值,进而避免拷贝(C++ 移动赋值函数本质只需要交换指针,所以很快)。或者,我们可以用STL共有的函数swap()来交换两个容器内的元素。
1 | vector <string> vec1,vec2; |
下面将具体分析几个常用的容器。
对于std::vector,其瓶颈在于对对象的析构和初始化,以及扩容时的拷贝开销。前者只能通过自己写vector来实现,并不推荐。而后者在很多时候是可以预测的,例如我们用vector来模拟栈在尾部进行push_back和pop_back操作时,当我们知道vector最大可能的容积的时候,应该使用reserve函数提前预留空间。这么做会使得小数据时性能有所损失,但在数据量跑到极限的情况下可以免除拷贝数组的开销,能使趋向极限情况时候常数减半。同时,如果需要用vector作为一个临时的局部数组,也应该使用resize()先指定大小或者在初始化的时候直接指定,不要一个一个的push_back()。
对于std::stack,其本质是一个容器适配器,它知识对内部容器的包装,而内部容器只需提供size(),push_back(),pop_back()等接口即可。其默认是用std::deque作为适配器,这样可以保证每次添加元素都是严格的O(1)。但是,众所周知的是deque的常数巨大无比,因此这样很容易导致效率低下。笔者的建议是使用类似 std::stack<int,std::vector<int>>来使用一个基于vector的stack。
对于std::priority_queue,其是一个堆,在不开-O2优化时候较慢,但是开了-O2后和手写效率差距在2倍以内,属于勉强可以接受的程度。其默认是小根堆,如果要用大根堆可以把数字取负后存储。对于要维护恰两个信息的堆也可以使用 std::pair 来维护。
对于std::map,其本质是一颗红黑树,查询元素基于 < 运算符(判断相等即 a < b && b < a),最坏查询复杂度为log(n)。如果你的map仅仅在一开始需要初始化,之后就不再修改元素,你可以使用结构体排序代替。具体见如下代码:
1 | int n; |
对于std::unordered_map,其本质是一个散列表,但是其常数巨大而且容易出现hash碰撞,因此为了防止被hack请书写hash函数。(from CodeForce)
1 | struct custom_hash { |
除此之外,在 1e5 到 1e6 的数量级下,你可以把unrodered_map认为是一个常数大约为map 1/8 到 1/4的一个map,其相距map优势并不是很大。当然,你依然可以做出针对性优化。你可以使用reserve()函数来为其预留足够的桶的大小,一定程度上减小时间。(一般来说桶越大,效果越好)
最后简单总结下,其实根据作者经验,在开O2的情况下,STL容器的效率已经是相当的高了,可以说完全不需要担心和手写的容器之间的效率差距。但是,对于极端毒瘤卡常题目,还是老老实实手写吧。
2023/02/03 补充一点: 当你自己在写一些类的时候,如果其移动成本相对较低但是复制成本相对较高,那么请您考虑在移动构造函数和移动赋值运算符上使用 noexcept 关键词,特别是与 STL 容器结合使用的时候。这是因为 noexcept 表明不会抛出异常,这会使得编译器对代码做出更多的优化。不仅如此,很多 STL 容器有严格的强异常规范(例如vector 的 push_back())操作,其在扩容等操作的时候只会对移动构造是 noexcept 的类进行移动原有数据,否则会调用更缓慢的拷贝构造,这样可能让你的程序莫名其妙地变慢,而且难以察觉,具体可以看看 <a href="{% post_path vector %}#push-back-和-emplace-back"> 这个 </a>
一些更加高级的技巧与思想
如果是以上的优化还是处于比较直观、容易理解范围内,那么下面涉及的优化可能就需要一定的CPU相关的知识了。
cache机制的利用
内嵌汇编(最终杀器)
参考资料
- 骆可强《论程序底层优化的一些方法与技巧》
- 骗分导论(OI) by 李博杰
未完待续……(咕咕咕,肝不动了)
 Wechat
Wechat






